Table of Contents
We write JS code, and then send it to the client’s browser, where it is executed. I wanted to understand more about what goes on under the hood. Turns out, there are a lot of very interesting optimizations and tricks that browsers use to make our code run faster. To write better code, in general, it’s good to have an understanding of how the code we write is going to be executed.
This post contains my notes made while exploring the same. I mostly referred Steve Kinney’s course on JavaScript Performance on Frontend Masters, and V8’s documentation.
Overview of JS Code Execution Process
JavaScript is a compiled language. Browsers use just-in-time (JIT) compilation, meaning that it will get compiled moments before execution.
Different browsers have different JS engines. Safari’s is called JavaScriptCore. Firefox’s is called SpiderMonkey. Chrome’s JS engine is called V8. We’ll focus on Chrome’s JS engine, V8, and see how our code’s journey through it. The following diagram shows the high level overview of this whole process.
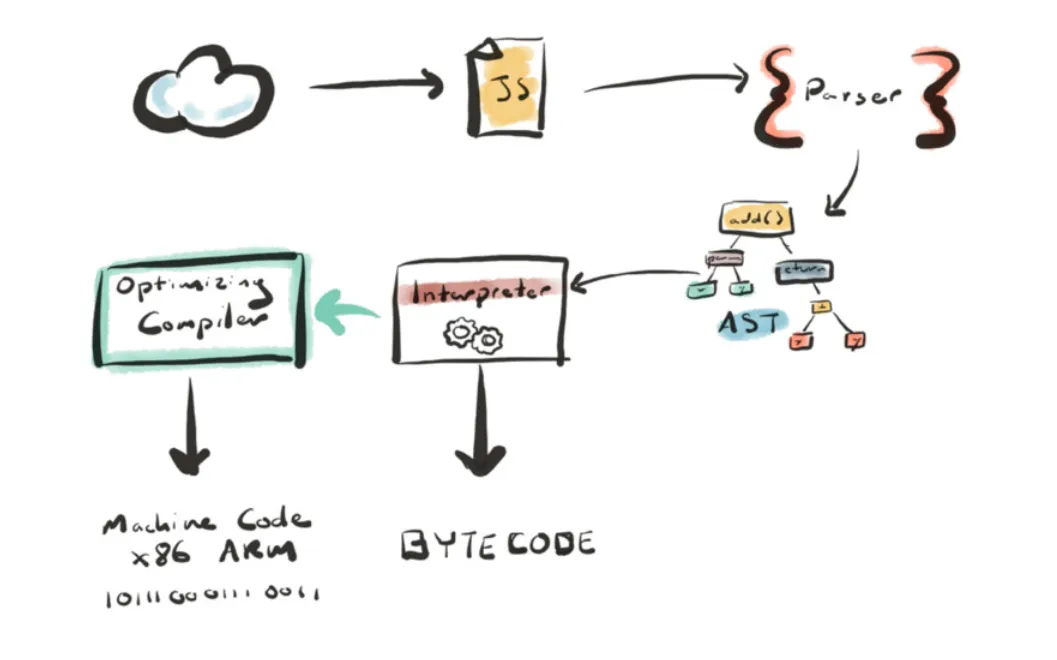
First, the browser downloads the JS code. Once downloaded, it will “parse” it. Before parsing, the JS code is just one long string of text. Parsing will convert it into something called as an Abstract Syntax Tree, which is a data structure that represents the code. That then goes to a “interpreter”. Chrome’s interpreter is named “Ignition”. Ignition will turn your AST into bytecode, which is what can be executed by the browser. Apart from the interpreter, there is a second compiler called as the “Optimizing Compiler”, which looks at the code and tries to make it even faster. It does so by attempting to converting the optimizable code into machine code. The optimizing compiler in V8 is named “TurboFan”.
Parsing
The source code is the true “intention” of the application, but the engine needs to figure out what that means. Parsing is the process of doing exactly that. Parsing will convert the long string of text JS code into a data structure that represents our code, called Abstract Syntax Tree (AST).
Parsing happens in two phases -
- Eager Parsing (Full parse): The code is parsed completely, it will take the code, and convert it to AST.
- Lazy Parsing (Pre parse): In this case, the parser will do the bare minimum work “now”, and will parse it completely “later”. Anything that you don’t need to parse now, it won’t parse it now.
Lazy Parsing is the browser’s way of trying to make our application faster. Browser will scan through the top level scope, and parse all the code it sees that’s actually doing something. It will skip things like function declarations and classes for now. Those will actually get parsed when they’re needed.
Generally speaking, lazy parsing is a good thing in terms of performance. But, sometimes, it might backfire. Take a look at the example below -
// these will be eagerly parsed
const a = 1;
const b = 2;
// here, it will just take note of the function declarationg, but won't parse the body
function add(a, b) {
return x + y;
}
add(a, b); // whoops, go back and parse add()As you see, the add function is being parsed twice, once lazy and immediately eagerly after. Sure, this example is pretty contrived, but it represents a point.
There is a way to force browser to eagerly parse something and skip lazy parsing. You can just add parenthesis around a function to force eager parsing.
// parse it asap. don't skip it and parse lazily
(function add(a, b) {
return x + y;
});This doesn’t mean that you should always wrap your functions with parenthesis. It is helpful to know that it happens, but it’s better to let browser do it’s thing. Also note that this might vary a lot one browser implementation to other, we are just talking about Chrome right now.
Once Parsing is done, we have the AST. AST can now be sent to Ignition (the interpreter) which will make Bytecode out of it. Once it has bytecode, then our JS code will actually get executed. But wait, there’s an important step in between. There is a optimizing compiler that will try to make this process even faster. Let’s see how it does that.
TurboFan - The Optimizing Compiler
TurboFan is an “optimizing compiler”, meaning that it will generate optimized native machine code. This process is also called as “Just in Time Compilation”. The optimized native machine code will take much less time to be executed, and thus, will improve performance. Two questions arise:
- How does TurboFan do this?
- More importantly, what can we devs do to help TurboFan to make our code faster?
Let’s try to understand this. Let’s take example of the add function
function add(a, b) {
return a + b;
}How will TurboFan try to optimize our code? We’ll see three main ways TurboFan uses- Speculative Optimization, Hidden Classes, and Function Inlining.
1. Speculative Optimization
- At the start, it will use the interpreter directly because optimizing compiler (TurboFan) is slow to get started, because at the start, TurboFan does not know anything about our code. It needs some information about the code before it knows whether it can optimize the code.
- JS is dynamic and not a typed language, so it doesn’t know that it will get two numbers every time. Interpreter will go ahead, figure out the types, and execute it. Interpreter starts gathering “feedback” about what it sees as the function is used.
- Once it knows enough about the function, let’s say that it’s getting called by two numbers all the time. Then, TurboFan can make the decision to assume that numbers are going to get passed in every time and it will optimize the function according to that assumption.
- But, what if then the function gets called and a string is passed in as one of the arguments? In that case, the assumption fails. At that point, TurboFan will deoptimize and send it back to Ignition for normal interpretation.
- So, TurboFan will optimize for what it has seen. If it sees something new, then that’s problematic.
- If you think about it, this also implies that there are potential performance gains if you use something like TypeScript, or Flow. Yes, they get compiled to JS, but since in your code you are enforcing types, you are helping TurboFan to do it’s more effectively.
- What about objects? How does speculative optimization work on objects? In case of objects, we know that since JS is dynamic, objects can be of any shape. TurboFan classifies them into three types
- Monomorphic: This means that based on what it has seen, the object has one defined shape. So, the function can be optimized, since we can expect the object in the next iterations to be of the same shape.
- Polymorphic: Polymorphic means that it has seen similar shapes before, so it will try to check which matches and optimize it.
- Megamorphic: In this case, it cannot definitively decide the shape of the object, because there’s too much variation between iterations. So, it will just call it a day and let Ignition take care of it. TurboFan won’t try to optimize the function in this case.
2. Hidden Classes for optimizing dynamic property lookups
- JS is a dynamic language, which means that properties can easily be added or removed from an object after its instantiation whenever you want.
- In a non-dynamic language, like Java, all of an object’s properties are determined at compile time, and cannot be dynamically added or removed at runtime. So, the values of properties, or the pointers to those properties can be stored as a contigous buffer in memory, whose size and length can be known. This isn’t possible in JS since object’s shape and property’s type can change at runtime.
- So, retrieving the value of a property (property lookup) in JS is more computationally expensive than in a non dynamic language. To make this faster, V8 uses a different method: hidden classes.
- V8 attaches a hidden class to each and every object, and it’s purpose is to optimize the property access time.
- Hidden classes work similarly to fixed object layouts used in languages like Java, but they are hidden at runtime.
- Then, V8 (or TurboFan, to be specific) does something called Inline Caching. It maintains a cache of the type of objects that were passed as a parameter in recent method calls, and uses that information to make an assumption about the type of object that will be passed as a parameter in the future.
- If it is able to make a good assumption about the type of object that will be passed to a method, it can bypass the process of figuring out how to access the objects properties, and instead use the stored information from previous lookups to the objects hidden class.
- The takeaway for us is that we should try to initialize the properties of our objects at creation, in the same order, and try not to modify them after initializing.
- Again, if you think about it, using TypeScript (or Flow) will force you to do all this.
3. Function Inlining
- If TurboFan sees that you are calling a function over and over again, it will go ahead and “rewrite” the code so that you are not calling that function.
- You don’t have to worry about this, it will take care of it on it’s own.
That’s pretty much it for this post. I’ll keep updating this as I discover more about the V8’s internal working. See you in the next one!
Resources
